Как я теорию 6-ти рукопожатий проверял. Часть 1
Чтобы получить более менее репрезентативную выборку я взял несколько человек из разных категорий. В первую я поместил своих знакомых по школе. Во вторую знакомых по универститету. И выбрал несколько человек из студентов, у которых мне довелось вести занятия, по одному человеку с учебного года. Так как часть преподавателей тоже пользуются вк, и в свое время преподавали у меня, можно было надеяться на то, что получится построить цепочки связей.
Итого, у меня было 9 исходных человек:
-
2-е школьных знакомых(по одному на каждую школу, в которых я учился);
-
2-е знакомых по университету(по одному на каждый университет, в которых я учился/работал);
-
5 студентов. 4 из университета моего профиля и один по смежному (я математик, а он - физик из другого университета).
Далее я собирался взять данные по друзьям и друзьям друзей этих людей. Записать все в БД, построить граф отношений, а дальше уже пытаться анализировать.
Готовим БД
В качестве БД было решено выбрать postgres (как раз опыта работы с базой было много, а вот случая на попробывать те самые рекурсивный запросы как-то все не находилось). В общем, были созданы следующие таблицы.
Непосредственно под пользователей:
create table users
(
id serial not null constraint users_pkey primary key,
vk_id integer,
data jsonb,
);
и под отношения:
create table friends
(
user1_id integer constraint friends_users_vk_id_fk references users (vk_id),
user2_id integer constraint friends_users2_vk_id_fk references users (vk_id),
id serial not null constraint friends_pkey primary key
);
А вот схема:
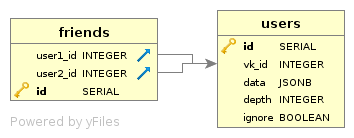

Поля в таблице friends ссылаются на vk_id поле таблицы users.
Стягиваем данные
Для стягивания данных я выбрал scrapy, для хранения быстрых данных взял монгу, ну и для непосредственного заполнения БД -- peewee. Для доступа к данным вконтакте дергал vk.api напрямую.
Вот что у меня получилось:
# file: ./vk/db.py
import peewee
from playhouse.postgres_ext import PostgresqlExtDatabase, BinaryJSONField
from vk.settings import DATABASE_CONNECTION
# настройки подключения к БД
db = PostgresqlExtDatabase(
register_hstore=False,
**DATABASE_CONNECTION
)
# базовая модель
class BaseModel(peewee.Model):
id = peewee.PrimaryKeyField()
class Meta:
database = db
# пользователи
class Users(BaseModel):
vk_id = peewee.IntegerField(index=True)
meta = BinaryJSONField()
depth = peewee.IntegerField()
# связи между пользователями
class Friends(BaseModel):
user1_id = peewee.IntegerField(index=True)
user2_id = peewee.IntegerField(index=True)
# чтоб вручную таблички не создавать, можно будет просто запустить скрипт
if __name__ == '__main__':
db.create_tables([Users, Friends])
Описание pipeline:
# file: ./vk/pipelines.py
from .db import Users, Friends
class VkPipeline(object):
CHUNK = 1000 # для оптимизации, будем писать в БД по 100 записей за раз
def open_spider(self, spider):
self.users = set([i.vk_id for i in Users.select(Users.vk_id)]) # чтобы не задваивались пользователи
friends = list(Friends.select()) # чтобы не задваивались отношения
self.friends = set([(i.user1_id, i.user2_id) for i in friends] + [(i.user2_id, i.user1_id) for i in friends])
self.users_to_go = [] # чанк на запись пользователей в БД
self.friends_to_go = [] # чанк на запись отношений в БД
def insert(self, lst, Model, force=False):
# метод для записи чанка в БД
if lst and (force or len(lst) % self.CHUNK == 0):
Model.insert_many(lst).execute()
del lst[:]
def close_spider(self, spider):
# по завершению работы спайдера дописываем в БД незаполненые полностью чанки
self.insert(self.users_to_go, Users, force=True)
self.insert(self.friends_to_go, Friends, force=True)
def process_item(self, item, spider):
# собственно подготовка данных на запись
if item['id'] not in self.users:
if item['first_name'] != 'DELETED':
self.users_to_go.append({'vk_id': item['id'], 'meta': item, 'depth': item['depth']})
self.users.add(item['id'])
if 'parent_id' in item:
pair = (item['parent_id'], item['id'])
if pair not in self.friends:
self.friends.add((item['parent_id'], item['id']))
self.friends.add((item['id'], item['parent_id']))
self.friends_to_go.append({'user1_id': item['parent_id'], 'user2_id': item['id']})
self.insert(self.users_to_go, Users)
self.insert(self.friends_to_go, Friends)
return item
Сам скрапер:
# file: ./vk/spider/friends.py
import json
import scrapy
class VkFriendsSpider(scrapy.Spider):
name = 'vk_friends'
allowed_domains = ['vk.com']
start_urls = ['http://vk.com/']
def get_url(self, id):
return 'https://api.vk.com/method/friends.get' \
'?user_id={id}&v=5.52&count=10000&fields=nickname,bdate,photo_200,education,city,sex'.format(id=id)
def start_requests(self):
urls = [("https://api.vk.com/method/users.get" \
"?user_id={id}&v=5.52&fields=nickname,bdate,photo_200,education,city,sex".format(id=_id),
_id) for _id in self.crawler.settings.get('START_IDS')]
for url, _id in urls:
yield scrapy.Request(url, callback=self.parse, meta={
'user_id': _id,
'depth': 1,
'proxy': self.crawler.settings.get('PROXY_URL')
}, cookies={'remixlang': 0})
def parse(self, response):
data = json.loads(response.text)
items = data['response']['items'] if 'items' in data['response'] else data['response']
for item in items:
item['depth'] = response.meta['depth']
if 'parent_id' in response.meta:
item['parent_id'] = response.meta['parent_id']
yield item
url = self.get_url(item['id'])
# контроль глубины
if response.meta['depth'] < self.crawler.settings.get('DEPTH'):
yield scrapy.Request(url, callback=self.parse, meta={
'parent_id': item['id'],
'depth': response.meta['depth'] + 1,
'proxy': self.crawler.settings.get('PROXY_URL')
}, cookies={'remixlang': 0})
Файл настроек:
# file: ./vk/settings.py
ITEM_PIPELINES = {
'vk.pipelines.VkPipeline': 100,
}
DOWNLOADER_MIDDLEWARES = {
"scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": 100,
}
START_IDS = [
123, # идентификаторы пользователей вконтакте, по которым будет строится база
124,
]
DEPTH = 3 # глубина поиска друзей
PROXY_URL = "http://188.40.141.216:3128" # прокся, подставьте какую-нибудь работающую
DATABASE_CONNECTION = {
'database': 'vk_parse',
'user': "user",
'password': "12345",
}
В общем, запустил я паука, а сам ушел пить чай, ибо дело это не быстрое. Как можно было предположить, размер данных возрастал с геометрической прогрессией. После того, как скрипт отоработал (прошло около получаса), у меня была база с полмиллионом пользователей. А связей и того больше - около одного миллиона.
Вникаем в рекурсивные запросы
Рассмотрим теперь, что это за запросы такие.
Сами рекурсивные запросы строятся с использованием конструкции WITH и добавлением магического слова RECURSIVE.
Я сначала построю простой cte запрос, который выведет третий уровень дерева отношения для пользователя с vk_id = 123, а потом переделаю его в рекурсивный запрос.
Чтобы просто вывести третий уровень, можно использовать такой запрос:
WITH level1 AS (
-- первый уровень (все друзья 123)
SELECT DISTINCT unnest(ARRAY [user1_id, user2_id]) AS id
FROM friends
WHERE user2_id = 123 OR user1_id = 123
), level2 AS (
-- второй уровень (все друзья друзей 123)
SELECT DISTINCT unnest(ARRAY [user1_id, user2_id]) AS id
FROM friends f
JOIN level1 l ON l.id = f.user1_id OR l.id = f.user2_id
), level3 AS (
-- третий уровень (все друзья друзей друзей 123)
SELECT DISTINCT unnest(ARRAY [user1_id, user2_id]) AS id
FROM friends f
JOIN level2 l ON l.id = f.user1_id OR l.id = f.user2_id
)
SELECT *
FROM level3
Графически данный запрос выдает все узлы, помеченные зеленым:
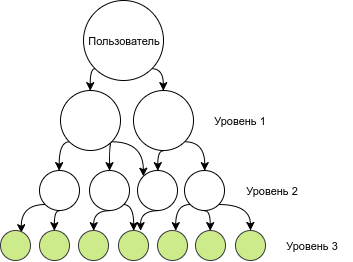

Но нас сами уровни не очень интересуют, интереснее построить цепочки отношений. C цепочками сложнее. Если пробовать строить все возможные цепочки, их количество будет очень быстро возрастать.
Сам запрос будет выглядеть следующим образом (тут я добавляю ARRAY поле chain в котором храню цепочки, и на каждом следующем уровне добавляю элементы):
WITH level1 AS (
-- первый уровень (все друзья 123)
SELECT DISTINCT
CASE WHEN user2_id = 123 THEN user1_id ELSE user1_id END AS id,
ARRAY[123, CASE WHEN user2_id = 123 THEN user1_id ELSE user2_id END] as chain
FROM friends
WHERE user2_id = 123 OR user1_id = 123
), level2 AS (
-- второй уровень (все друзья друзей 123)
SELECT DISTINCT
CASE WHEN l.id = f.user2_id THEN user1_id ELSE user1_id END AS id,
l.chain || CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END as chain
FROM friends f
JOIN level1 l ON l.id = f.user1_id OR l.id = f.user2_id
WHERE CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END != ALL(l.chain)
), level3 AS (
-- третий уровень (все друзья друзей друзей 123)
SELECT DISTINCT
CASE WHEN l.id = f.user2_id THEN user1_id ELSE user1_id END AS id,
l.chain || CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END as chain
FROM friends f
JOIN level2 l ON l.id = f.user1_id OR l.id = f.user2_id
WHERE CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END != ALL(l.chain)
)
SELECT *
FROM level3
На третьем уровне мой 4-х ядерный ноутбук начинал тарахтеть, но через пару секунд раздумй все же выдавал результат, содержащий ~650тыс строк. Ради интереса попробовал построить 4-ый уровень (цепочки длиной в 5 звеньев). На его постройку ушло почти 5 минут сложных и упорных расчетов. Результат содержал 56 миллионов различных вариантов. Очень хотелось взглянуть на 5-ый уровень, но времени не было и я пошел дальше.
Графически запрос выдает все возможные комбинации цепочек из 4 узлов. Например, такую:
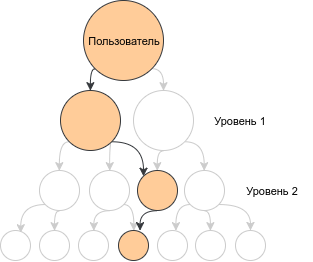
Если внимательно посмотреть на запрос, используемый для постройки 2-го и 3-го уровней, можно увидеть, что они отличаются только таблицей, используемой в JOIN; для 2-го уровня это таблица 1-го уровня; для 3-го уровня --таблица 2-го уровня.
В общем, тут наблюдаем индукцию в чистом виде. Где level1 опеределяет базу индукции, а level2 и level3, стало быть, определяют 1-ый и 2-ой индукционные шаги.
Вот и перепишем данный запрос, с использованием рекурсивного запроса. Получится вот что:
WITH RECURSIVE chains(id, chain, depth) AS (
-- основа индукции
SELECT
123,
ARRAY[123] AS chain,
0 AS depth
UNION
-- индукционный шаг
SELECT DISTINCT
CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END AS id,
l.chain || CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END as chain,
depth + 1 as depth -- увеличиваем уровень на 1
FROM friends f
JOIN chains l ON l.id = f.user1_id OR l.id = f.user2_id
WHERE CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END != ALL(l.chain)
AND depth < 3 -- условие остановки
)
SELECT *
FROM chains
База отделятся от индукционного шага с помщью UNION (главное, чтобы количество и типы столбцов в обоих запросах совпадали). И, что важно, нужно обеспечить возможность остановки рекурсивного запроса.
Рекурсивный запрос останавливается, когда результат текущего индукционного шага не содержит строк. То есть пуст.
Чтобы гарантировать остановку, мы добавляем поле depth, в котором храним текущий уровень дерева. Благодаря условию l.depth < 3, когда мы достигаем 3-го уровня, рекурсивный запрос гарантированно прекращает работу.
Если запустить этот запрос, мы обнаружим еще одно отличие - вместо только третьего уровня, он вернет нам все уровни в одном запросе.
То есть у нас будут встречаться неполные цепочки, которые могут заканчиваться, например, на втором уровне:
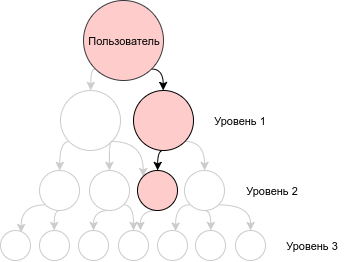

Чтобы исправить такое поведение, достаточно в основном запросе добавить условие на глубину дерева. В нашем случае достаточно заменить:
SELECT *
FROM chains
на:
SELECT *
FROM chains
WHERE depth = 3
В принципе, с этим запросом можно попробовать попроверять "теорию" 3-х рукопожатий. Что, тоже задачка, но не такая интересная для нас.
Как вы догадались, строить цепочки длиной 5 и более, а потом анализировать их - очень накладно (количество растет быстро и обыкновенная десктопная конфигурация, как правило, с такими объемами уже не справляется).
Решаем задачу
Однако, наша изначальная задача - это не поиск цепочек, а проверка теории 6 рукопожатий. Поэтому, второй моей идеей было - разбить множество пользователей на классы эквивалентности по отношению "друг моего друга - мой друг". Для этого я выбрал произвольного пользователя и построил следующий запрос:
WITH RECURSIVE level(id, depth) AS (
SELECT 123 as id, 0 as depth
UNION ALL
--
SELECT DISTINCT
CASE WHEN l.id = f.user2_id THEN user1_id ELSE user2_id END AS id,
l.depth + 1 as depth
FROM level l
JOIN friends f ON l.id = f.user1_id OR l.id = f.user2_id
WHERE l.depth < 6
)
SELECT count(DISTINCT id)
FROM level
Неожиданно получилось очень похожее на количество пользователей число. Я тут же запустил для сравнения следующий запрос:
SELECT count(*)
FROM users
Бинго! Размеры-то совпали. Что означало, что все пользователи в моей выборке связаны между собой не более, чем через 6 рукопожатий. Таким образом, формально, для данной выборки я утверждение доказал. Честно говоря, до последнего момента я не был уверен в положительном исходе.
Я также дополнительно проверил запрос с WHERE l.depth <= 5. Как оказалось, в моем случае и 5-ти рукопожатий достаточно. С 4-мя оставалось примерно 1000 не связанных человек.
Это, конечно, не значит, что данный результат соответствует любой выборке. Но, тем не менее, это показывает, что для группы лиц с разницей в возрасте до 10 лет получающих/получивших высшее образование по технической специальности, можно с большой вероятностью ожидать наличие общих знакомых.
Думаю, на этом пока остановлюсь. В следующей части я попробую решить задачу построения цепочек.
![]() postgresql,
python,
scrapy,
sql,
vk
postgresql,
python,
scrapy,
sql,
vk
![]()
![]()
![]()